Storage cluster performance on cloudscale
This page documents the performance of the VSHN Managed Storage Cluster on cloudscale.
The performance numbers presented on this page have been obtained from a storage cluster instance deployed on OpenShift 4.8. All performance numbers on this page have been measured on an otherwise idle storage cluster instance.
| The performance numbers presented on this page have been performed on a storage cluster with 3 nodes with 100 GiB storage usable by the storage cluster. |
| On cloudscale, the VSHN Managed Storage Cluster is hosted on block storage provided via the csi-cloudscale CSI driver. |
| The shaded areas in the graphs represent the standard deviation of the measured IOPS for each series of data points. |
Block storage performance
On cloudscale, block storage is not provided by the VSHN Managed Storage Cluster. Instead, block storage is provided via the csi-cloudscale CSI driver.
However, we still show the block storage performance numbers here to give you an idea of what levels of performance you can expect from cloudscale block storage.
The cloudscale CSI driver offers both ssd and bulk storage volumes.
Notably, bulk storage volumes are rate-limited to < 500 IOPS, as is clearly visible in the benchmark results below.
Also see the cloudscale pricing documentation.
On cloudscale, we setup storage classes called ssd and bulk which match the storage volume types offered by cloudscale
|
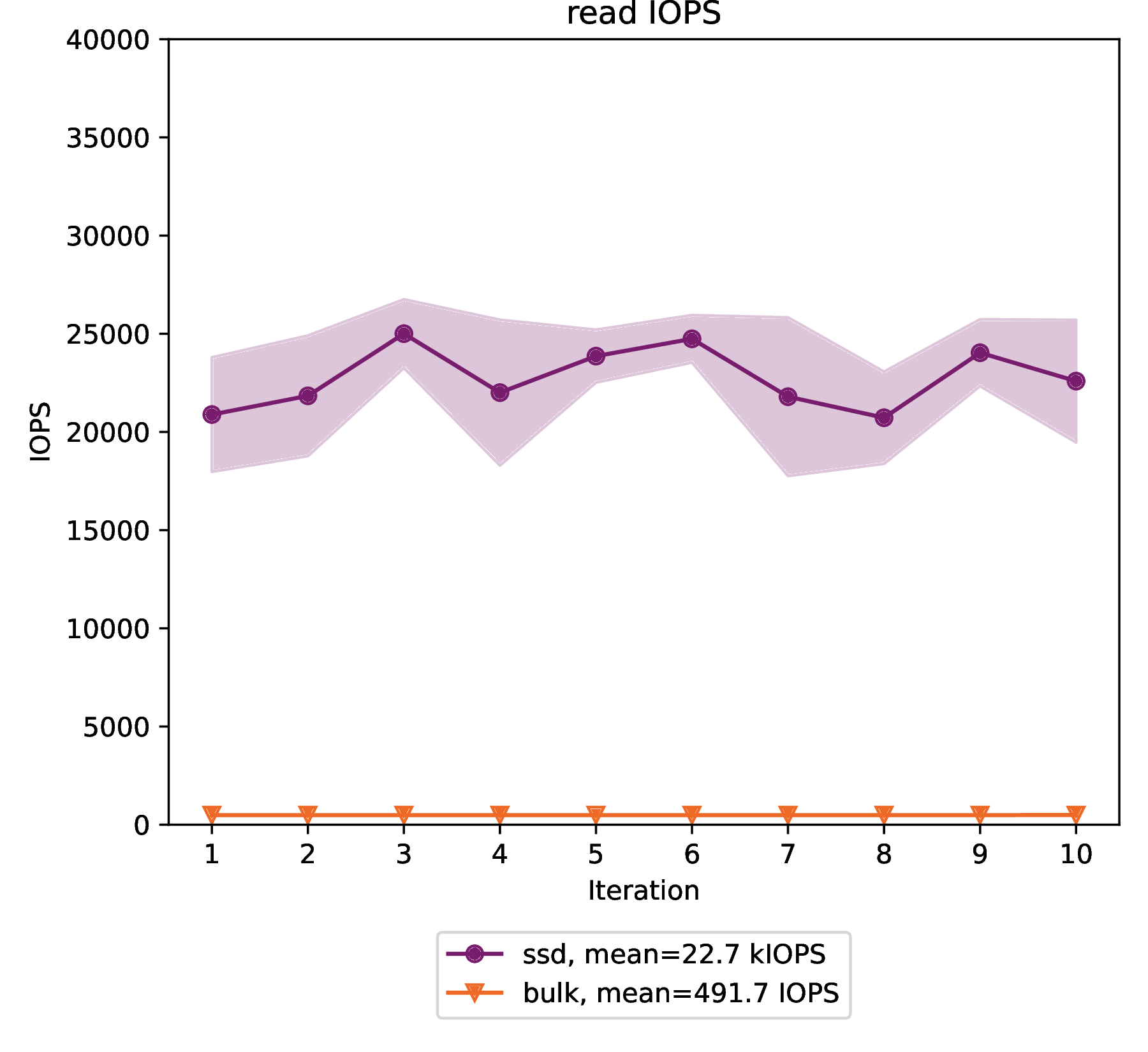
Read IOPS
The ssd volume type provides 22748 read IOPS on average with a standard deviation of 1558 IOPS over 10 benchmark iterations.
The bulk volume type provides 491 IOPS on average with a standard deviation of 0.5 IOPS over 10 benchmark iterations.
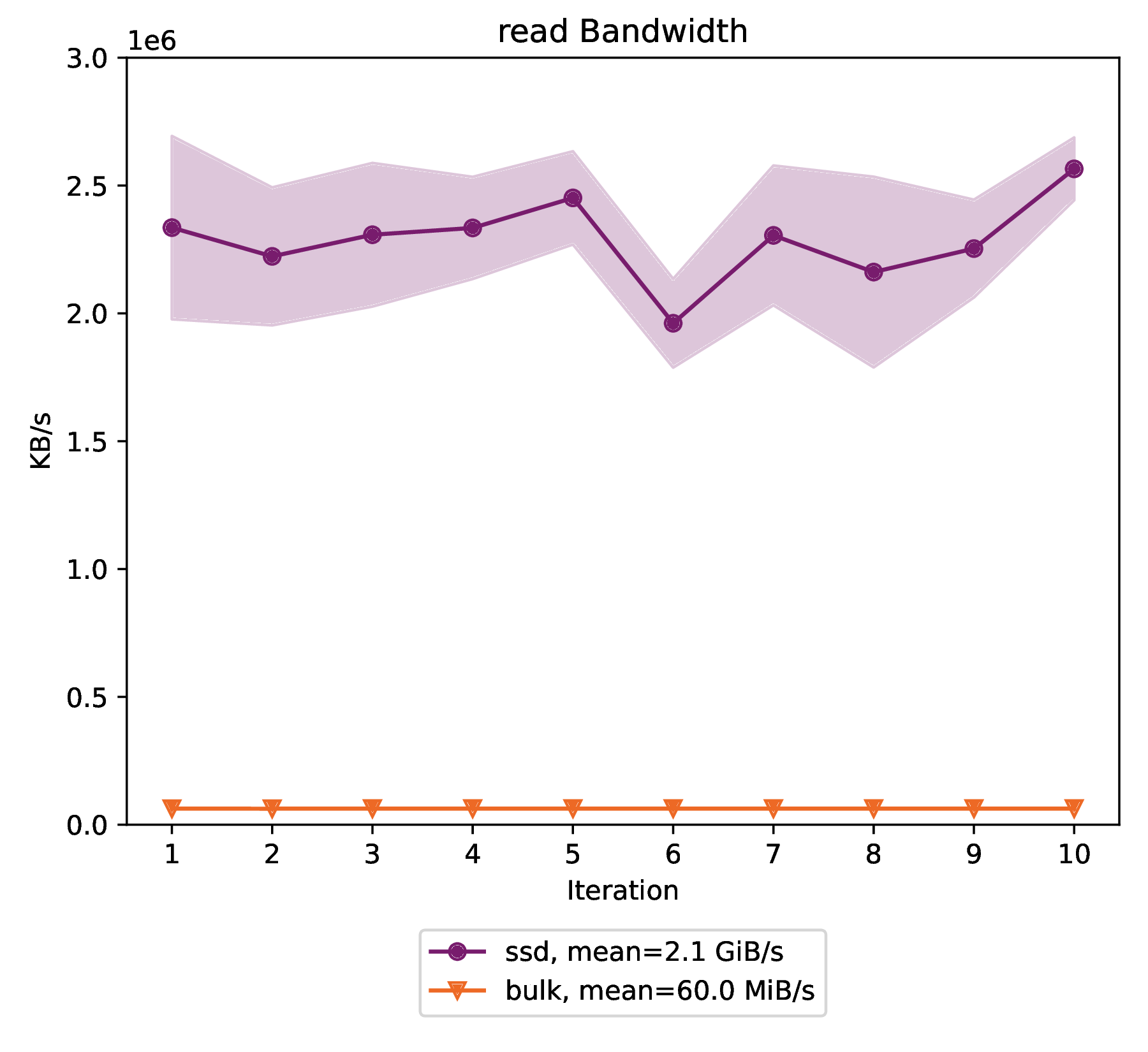
Read bandwidth
The ssd volume type provides an average read bandwidth of 2.133 GiB/s with a standard deviation of 154 MiB/s over 10 benchmark iterations.
The bulk volume type provides an average read bandwidth of 60.5 MiB/s with a standard deviation of 130 KiB/s over 10 benchmark iterations.
Write IOPS
Block storage write IOPS vary depending on the frequency of fsync calls.
The graphs below show write IOPS for different fsync frequencies for both ssd and bulk volume types.
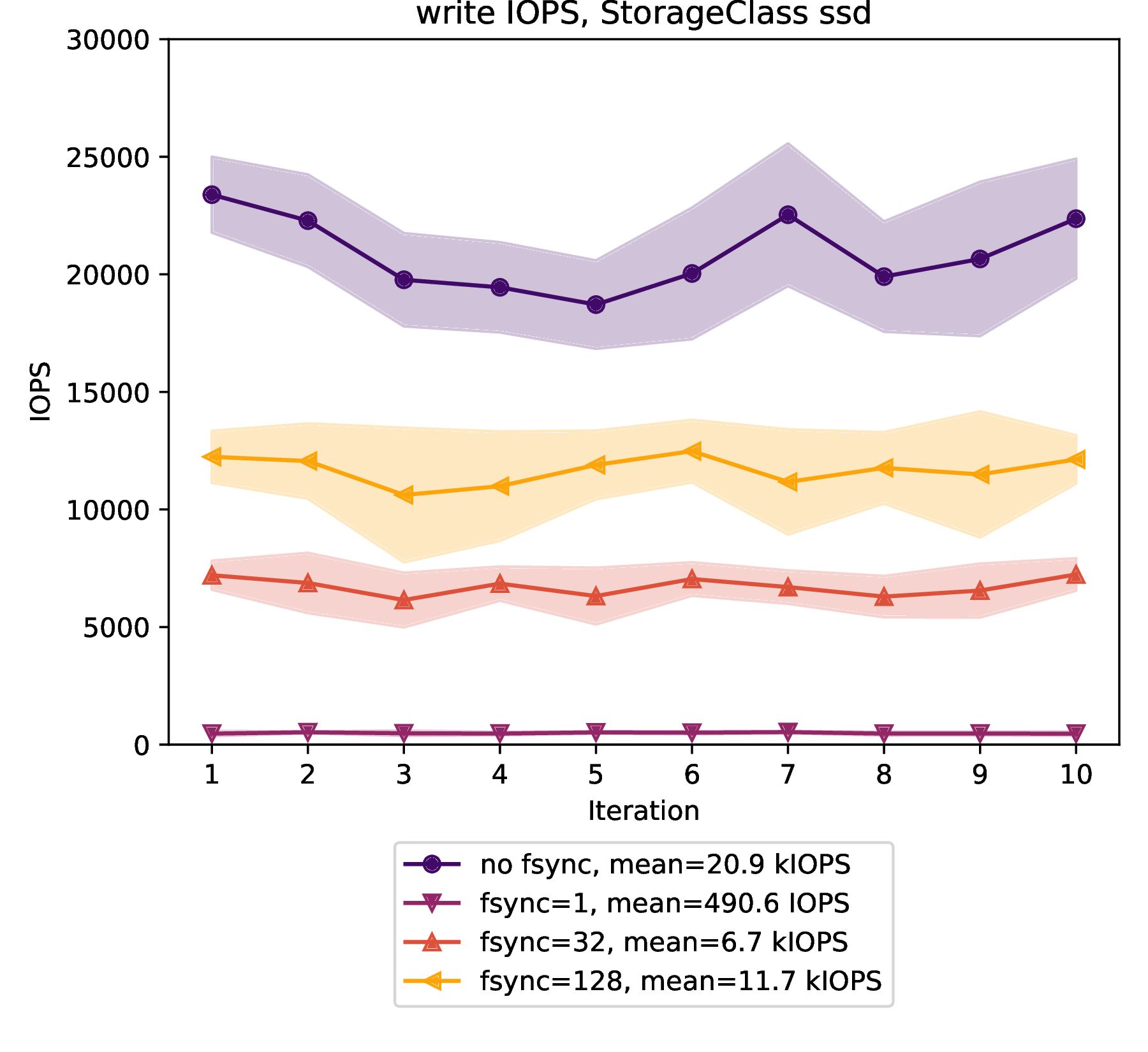
The ssd volume type provides:
-
20909 write IOPS on average with a standard deviation of 1594 IOPS over 10 iterations without calling
fsyncduring the benchmark ("no fsync"). -
490 write IOPS on average with a standard deviation of 27 IOPS over 10 benchmark iterations with an
fsynccall after each operation ("fsync=1"). -
6721 write IOPS on average with a standard deviation of 386 IOPS over 10 benchmark iterations with
fsynccalls after every 32 operations ("fsync=32"). -
11683 write IOPS on average with a standard deviation 601 IOPS over 10 benchmark iterations with
fsynccalls after every 128 operations ("fsync=128").
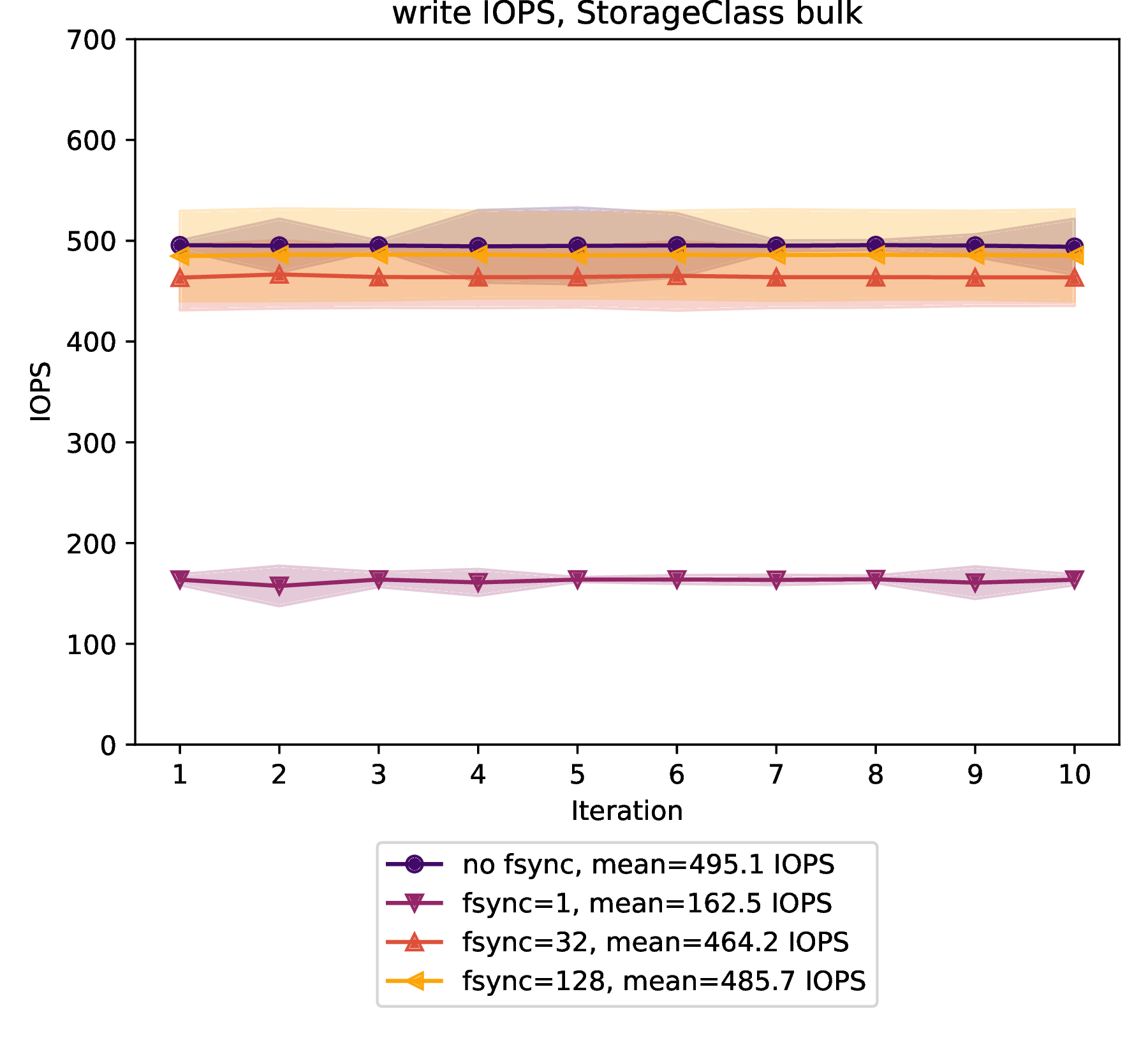
The bulk volume type provides:
-
495 write IOPS on average with a standard deviation of 0.5 IOPS over 10 iterations without calling
fsyncduring the benchmark ("no fsync"). -
162 write IOPS on average with a standard deviation of 2 IOPS over 10 benchmark iterations with an
fsynccall after each operation ("fsync=1"). -
464 write IOPS on average with a standard deviation of 1 IOPS over 10 benchmark iterations with
fsynccalls after every 32 operations ("fsync=32"). -
485 write IOPS on average with a standard deviation 0.5 IOPS over 10 benchmark iterations with
fsynccalls after every 128 operations ("fsync=128").
Write bandwidth
Block storage write bandwidth exhibits the same performance variation based on fsync frequency as block storage write IOPS.
The graphs below show write bandwidth for different fsync frequencies for both ssd and bulk volume types.
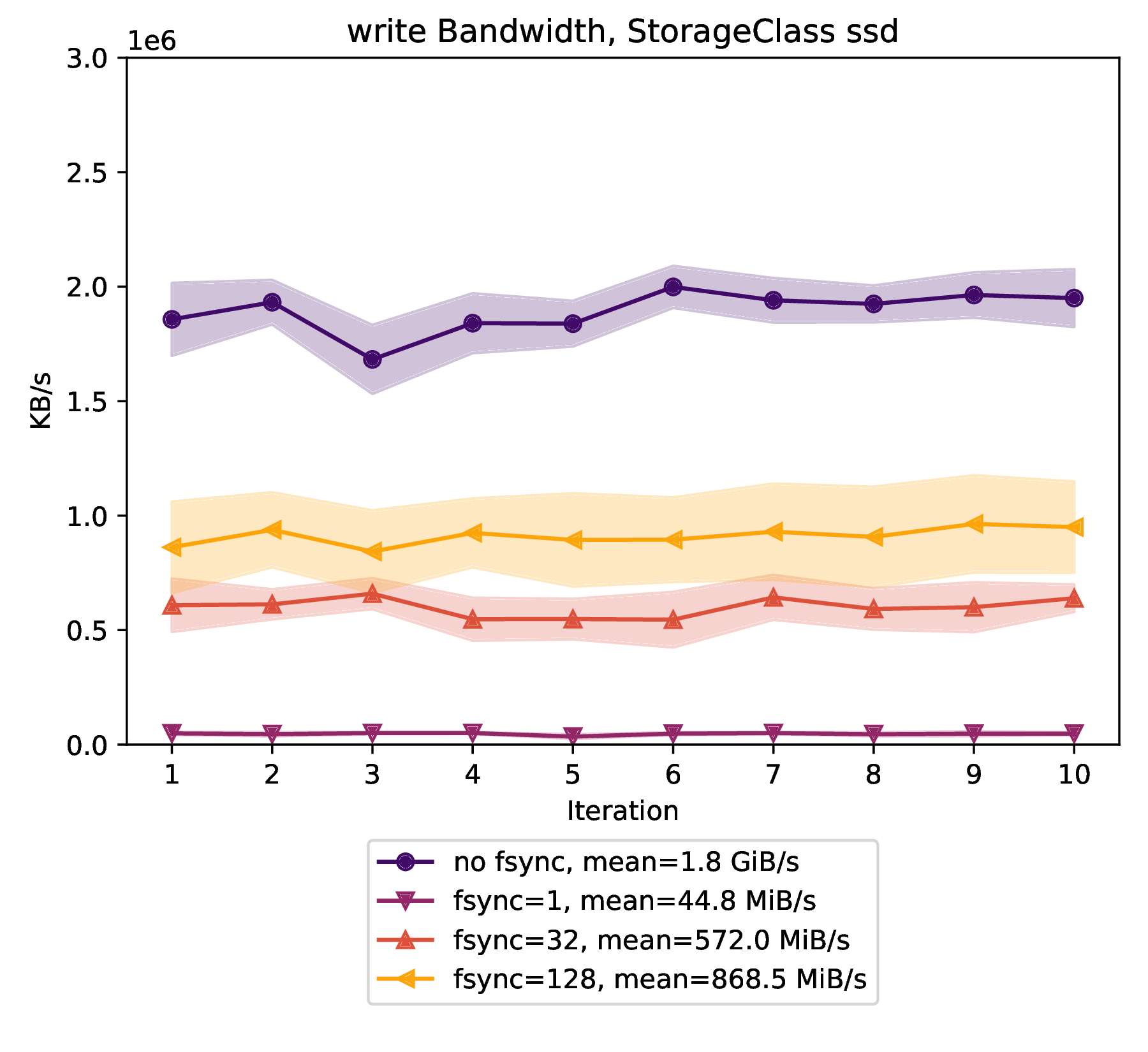
The ssd volume type provides a write bandwidth of:
-
1.763 GiB/s on average with a standard deviation of 154 MiB/s over 10 iterations without
fsynccalls during the benchmark ("no fsync"). -
44.8 MiB/s on average with a standard deviation of 4.3 MiB/s over 10 iterations with an
fsynccall after each operation ("fsync=1"). -
572 MiB/s on average with a standard deviation of 40 MiB/s over 10 iterations with
fsynccalls after every 32 operations ("fsync=32"). -
868 MiB/s on average with a standard deviation of 36.5 MiB/s over 10 iterations with
fsynccalls after every 128 operations ("fsync=128").
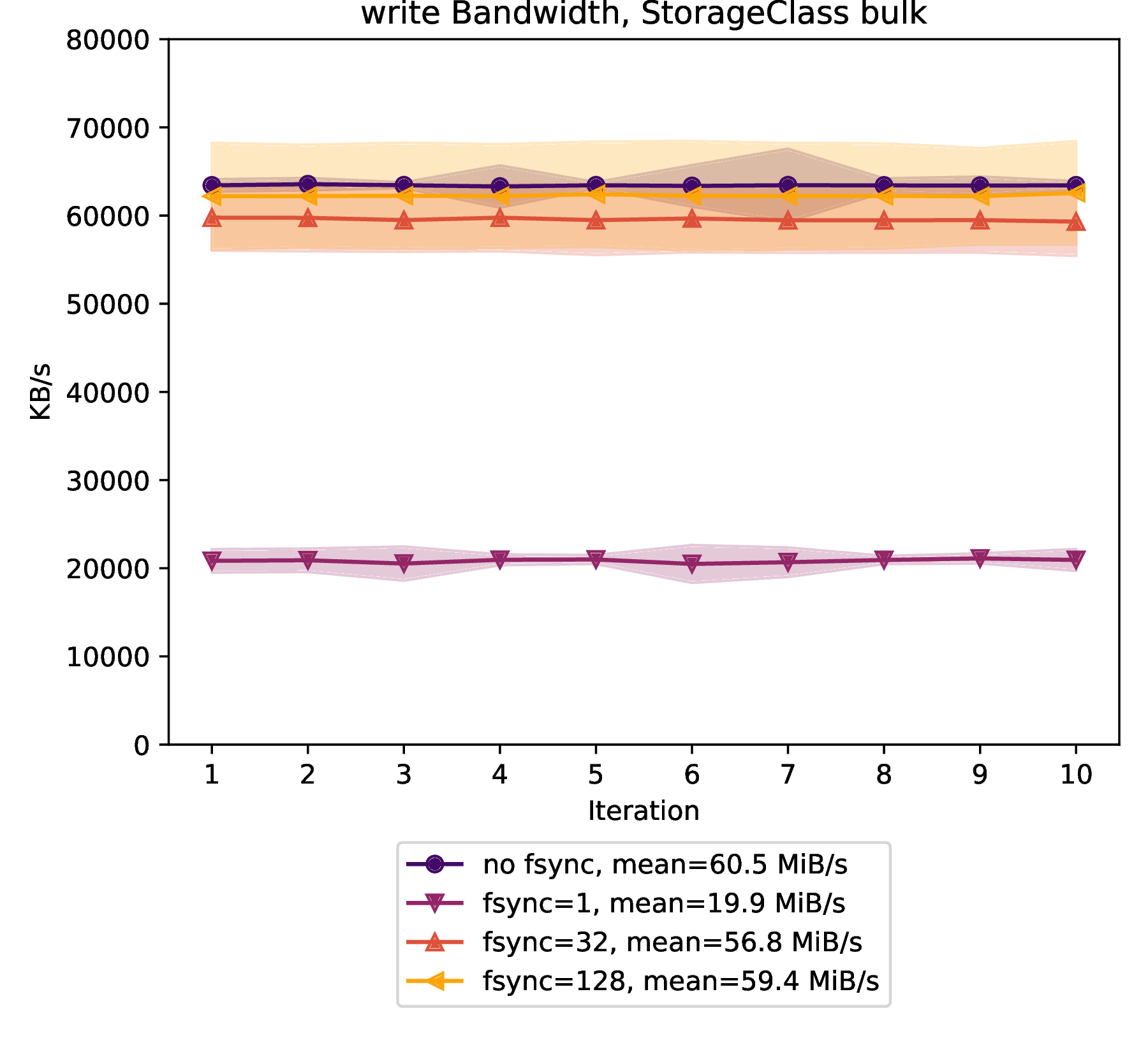
The bulk volume type provides a write bandwidth of:
-
60.5 MiB/s on average with a standard deviation of 129 KiB/s over 10 iterations without
fsynccalls during the benchmark ("no fsync"). -
19.8 MiB/s on average with a standard deviation of 65 KiB/s over 10 iterations with an
fsynccall after each operation ("fsync=1"). -
56.8 MiB/s on average with a standard deviation of 154 KiB/s over 10 iterations with
fsynccalls after every 32 operations ("fsync=32"). -
59.3 MiB/s on average with a standard deviation of 123 MiB/s over 10 iterations with
fsynccalls after every 128 operations ("fsync=128").
File storage performance
File storage is provided by CephFS.
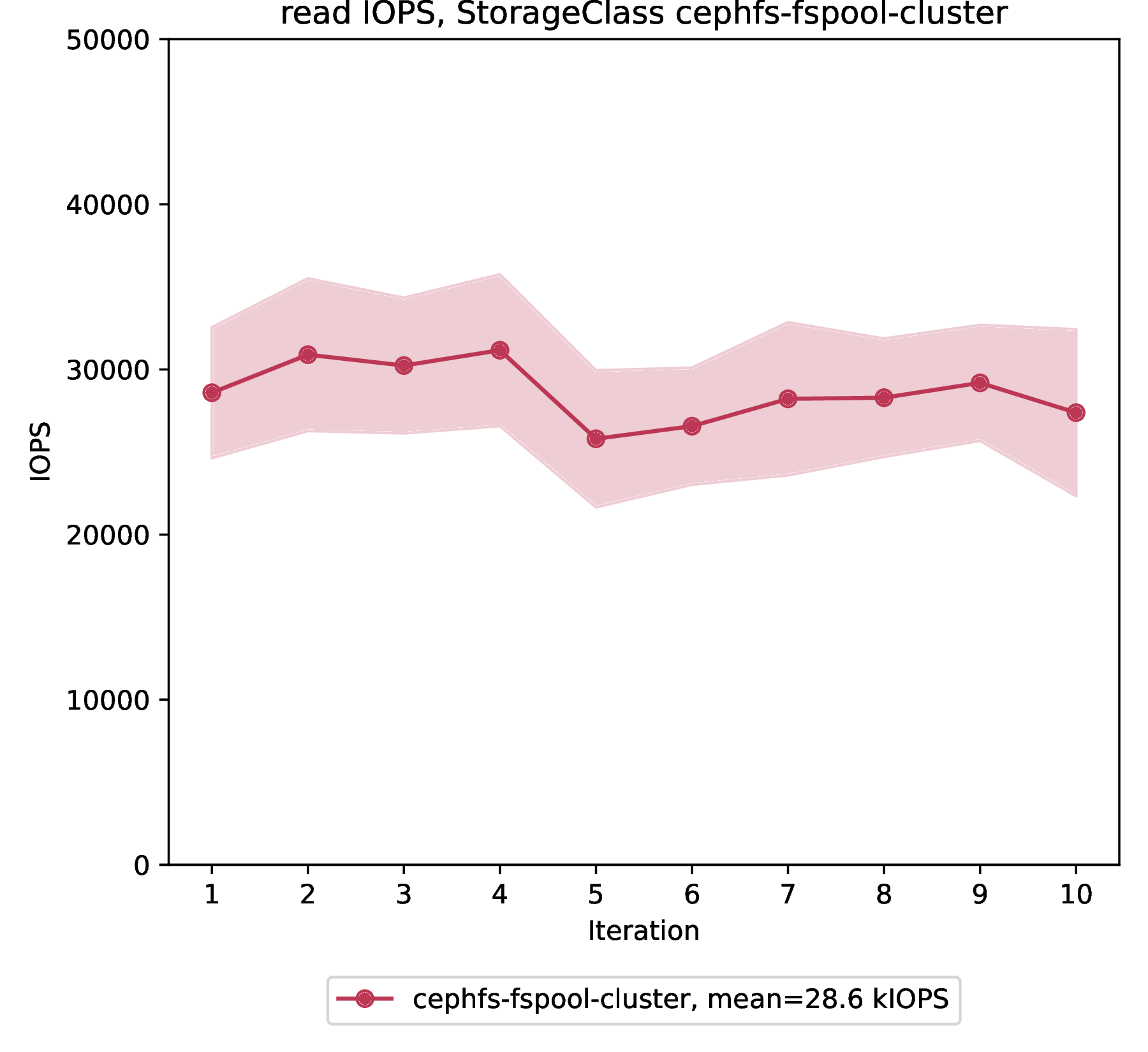
Read IOPS
File storage provides 28632 read IOPS on average with a standard deviation of 1781 IOPS over 10 benchmark iterations.
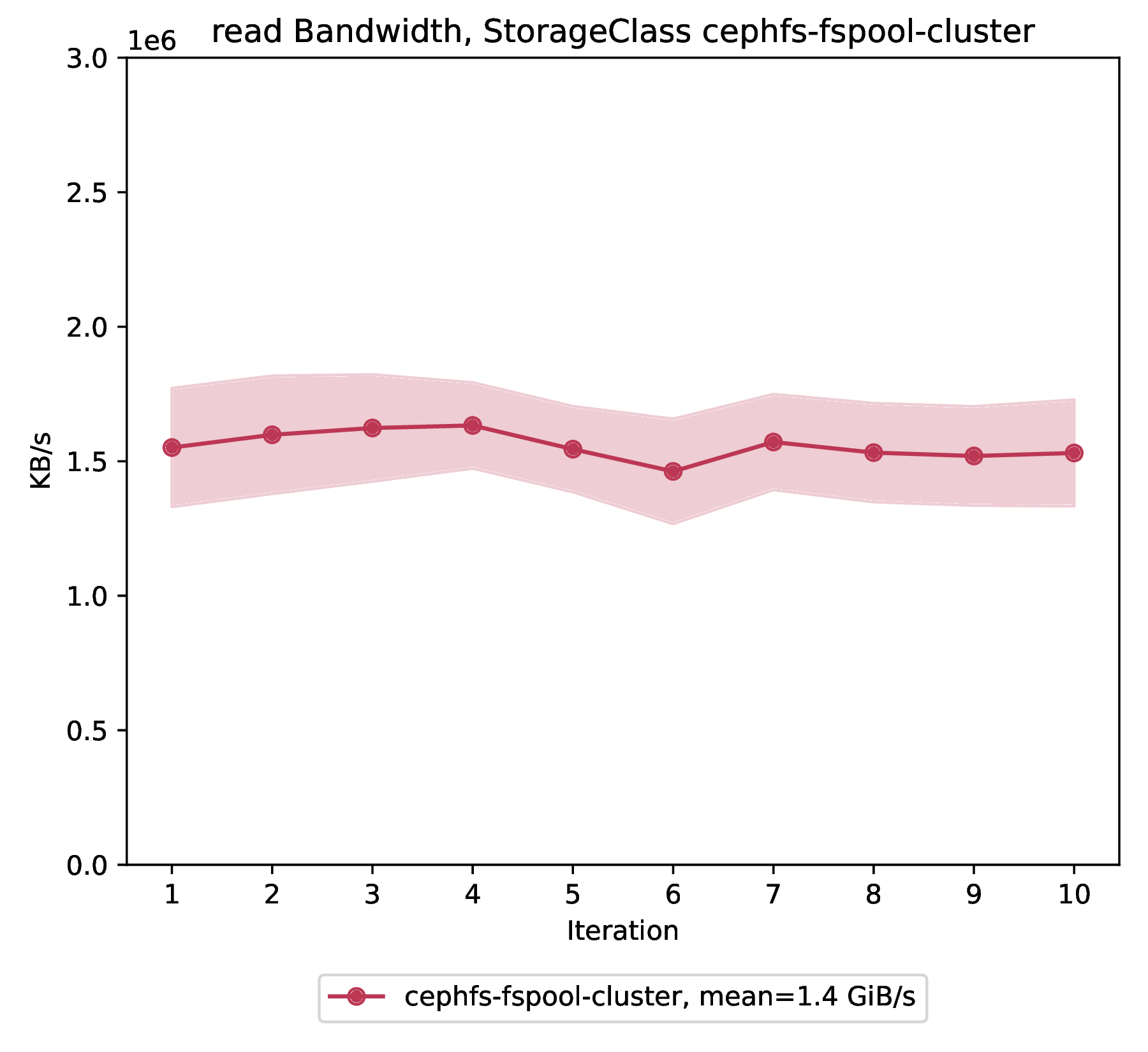
Read bandwidth
File storage provides an average read bandwidth of 1.45 GiB/s with a standard deviation of 49 MB/s over 10 benchmark iterations.
Write IOPS
File storage provides 5688 write IOPS on average with a standard deviation of 1781 IOPS over 10 benchmark iterations.
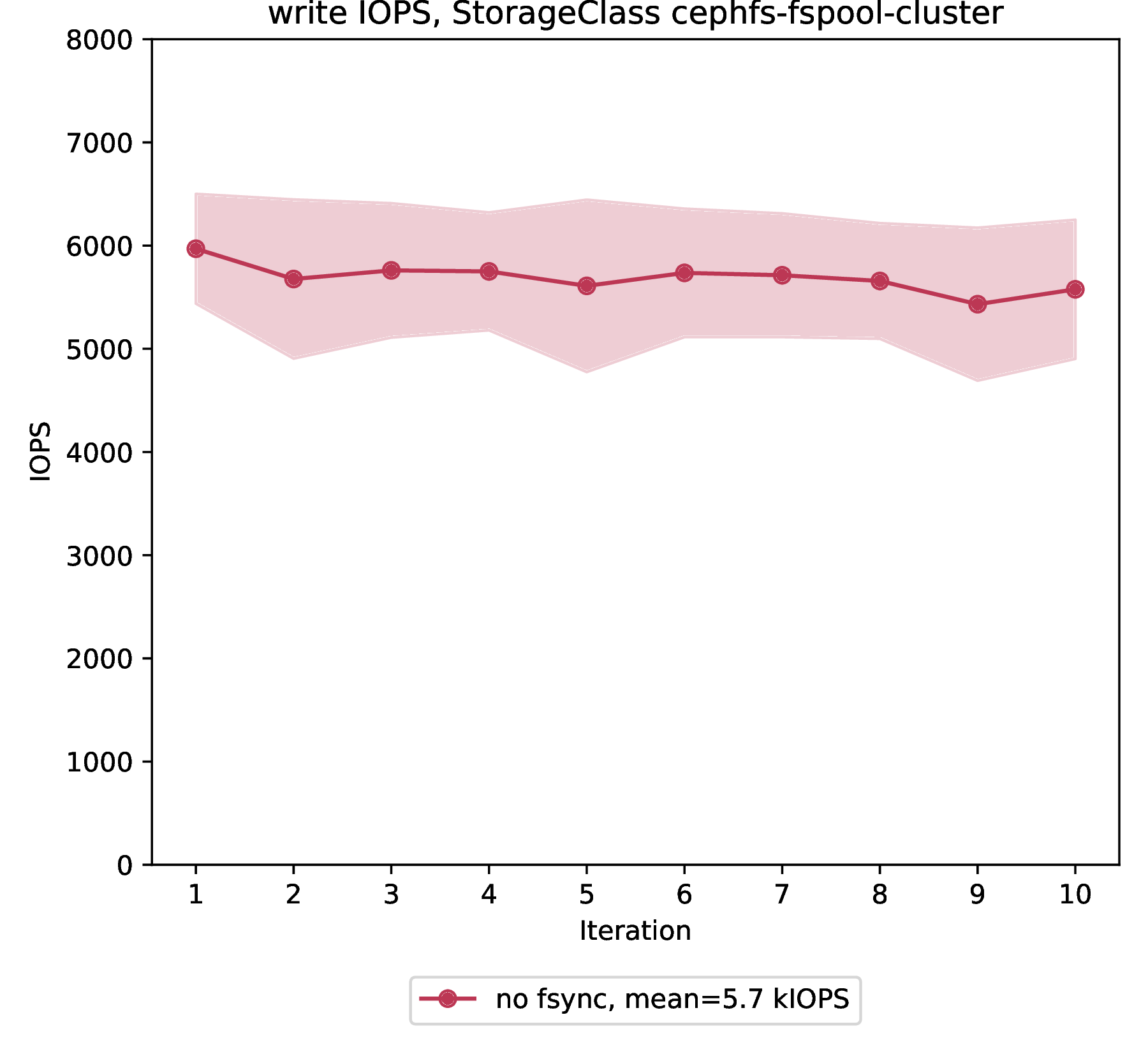
Since CephFS doesn’t provide full fsync support, we’re not showing results for different fsync frequencies.
The results presented here are obtained from a benchmark run with no fsync calls during each benchmark iteration.
Write bandwidth
File storage provides a write bandwidth of 195 MiB/s on average with a standard deviation of 4.8 MiB/s over 10 benchmark iterations.
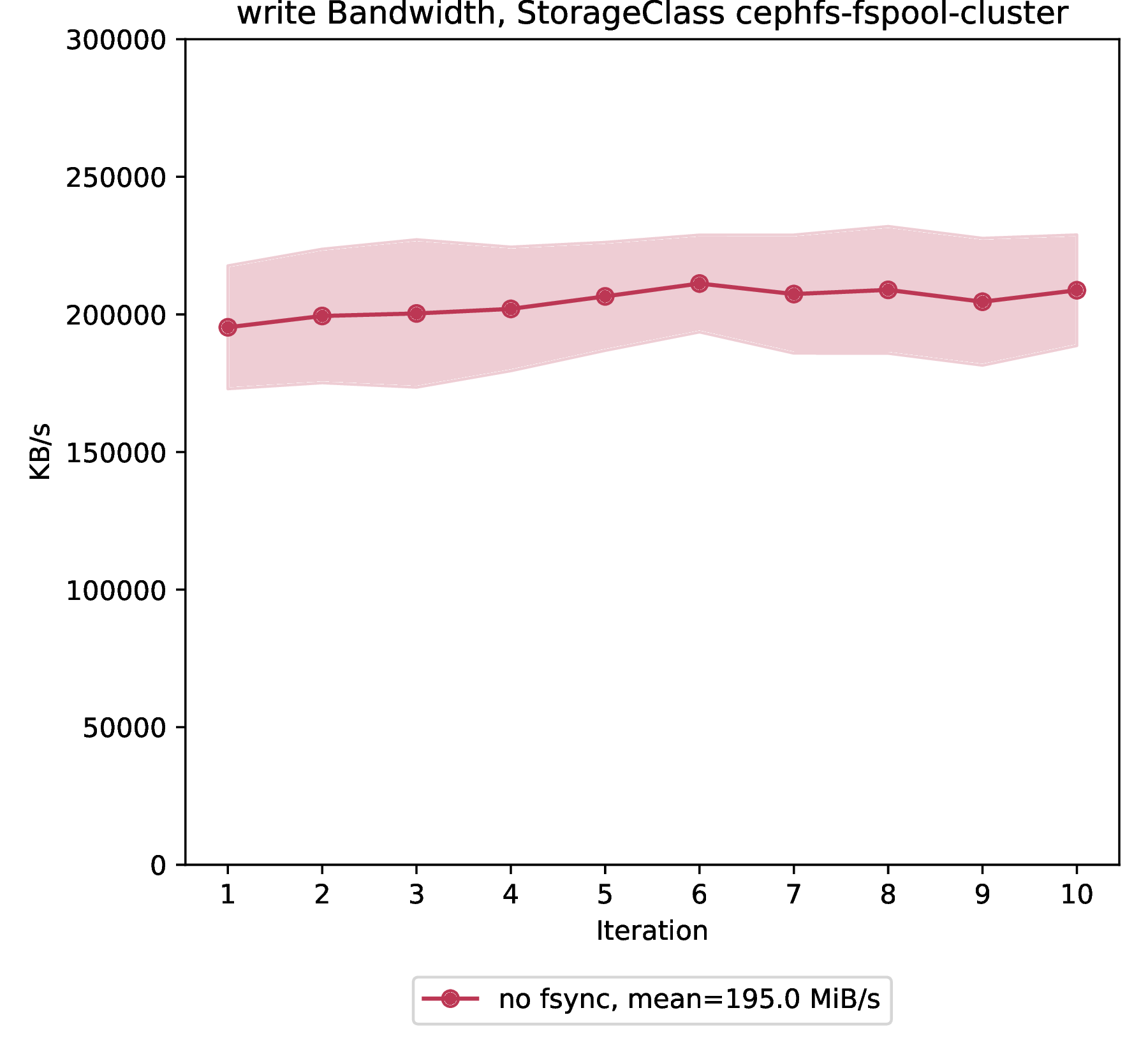
Once again, we’re not showing results for different fsync frequencies.
The results presented here are obtained from a benchmark run with no fsync calls during each benchmark iteration.